



by Maria Hornbek
Machine learning analyzed 3.5 million books to find that adjectives ascribed to women tend to describe physical appearance, whereas words that refer to behavior go to men.
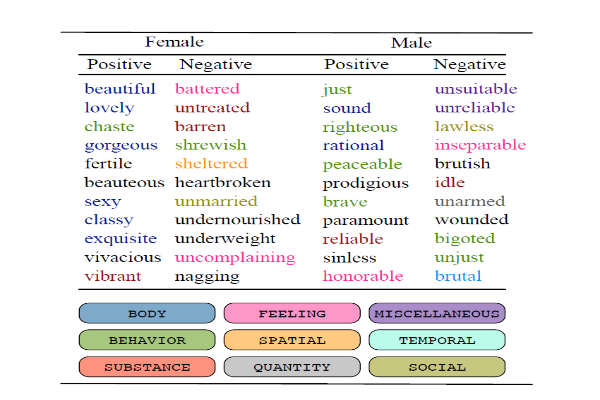
“Beautiful” and “sexy” are two of the adjectives most frequently used to describe women. Commonly used descriptors for men include righteous, rational, and courageous.
Researchers trawled through an enormous quantity of books in an effort to find out whether there is a difference between the types of words that describe men and women in literature. Using a new computer model, the researchers analyzed a dataset of 3.5 million books, all published in English between 1900 to 2008. The books include a mix of fiction and non-fiction literature.
“We are clearly able to see that the words used for women refer much more to their appearances than the words used to describe men. Thus, we have been able to confirm a widespread perception, only now at a statistical level,” says computer scientist and assistant professor Isabelle Augenstein of the University of Copenhagen’s computer science department.
The researchers extracted adjectives and verbs associated with gender-specific nouns (e.g. “daughter” and “stewardess”). For example, in combinations such as “sexy stewardess” or “girls gossiping.” They then analyzed whether the words had a positive, negative, or neutral sentiment, and then categorized the words into semantic categories such as “behavior,” “body,” “feeling,” and “mind.”
11 billion words
Their analysis demonstrates that negative verbs associated with body and appearance appear five times as often for female figures as male ones. The analysis also demonstrates that positive and neutral adjectives relating to the body and appearance occur approximately twice as often in descriptions of female figures, while male ones are most frequently described using adjectives that refer to their behavior and personal qualities.
In the past, linguists typically looked at the prevalence of gendered language and bias, but using smaller data sets. Now, computer scientists can deploy machine learning algorithms to analyze vast troves of data—in this case, 11 billion words.
Although many of the books were published several decades ago, they still play an active role, Augenstein points out. The algorithms used to create machines and applications that can understand human language are fed with data in the form of text material that is available online. This is the technology that allows smartphones to recognize our voices and enables Google to provide keyword suggestions.
Why do adjectives matter so much?
“The algorithms work to identify patterns, and whenever one is observed, it is perceived that something is ‘true.’ If any of these patterns refer to biased language, the result will also be biased. The systems adopt, so to speak, the language that we people use, and thus, our gender stereotypes and prejudices,” says Augenstein. She gives an example of where it may be important: “If the language we use to describe men and women differs in employee recommendations, for example, it will influence who is offered a job when companies use IT systems to sort through job applications.”
As artificial intelligence and language technology become more prominent across society, it is important to be aware of gendered language.
Augenstein continues: “We can try to take this into account when developing machine-learning models by either using less biased text or by forcing models to ignore or counteract bias. All three things are possible.”
The researchers point out that the analysis has its limitations, in that it does not take into account who wrote the individual passages and the differences in the degrees of bias depending on whether the books were published during an earlier or later period within the data set timeline. Furthermore, it does not distinguish between genres—e.g. between romance novels and non-fiction. The researchers are currently following up on several of these items.
Additional coauthors of the study are from the University of Maryland, Google Research Johns Hopkins University, the University of Massachusetts Amherst, and Microsoft Research.
They presented a paper on the at the 2019 Annual Meeting of the Association for Computational Linguistics.
*first published in: www.weforum.org
 By: N. Peter Kramer
By: N. Peter Kramer
